Estos son los pilares clave del tema:
1. Clasificación Funcional del Lenguaje (DDL, DML, DCL)
El documento estructura SQL no como un bloque monolítico, sino dividido por su propósito, lo cual facilita el estudio organizado:
- DDL (Data Definition Language): Capacidad para definir la estructura (tablas, índices, vistas) mediante
CREATE,ALTERyDROP. - DML (Data Manipulation Language): El núcleo para trabajar con datos. Incluye la potencia de las consultas (
SELECT) y la modificación de registros (INSERT,UPDATE,DELETE). - DCL y TCL: Control de seguridad (permisos) y gestión de transacciones para asegurar la integridad de los datos.
2. Fundamentación Teórica y Relacional
- Lenguaje Declarativo: Se enfatiza que el usuario especifica qué quiere y no cómo obtenerlo, delegando la optimización al SGBD.
- Álgebra Relacional: El tema conecta las operaciones de SQL con sus bases matemáticas, lo que permite entender por qué funcionan los
JOINo las operaciones de conjunto (UNION,INTERSECT).
3. Gestión de la Integridad y el Diccionario de Datos
- Integridad Referencial: Explica detalladamente cómo las claves foráneas mantienen la coherencia entre tablas.
- Metadatos: Un punto fuerte es la explicación de cómo el propio SQL consulta su estructura a través del Catálogo o Diccionario de Datos (
INFORMATION_SCHEMA), permitiendo que el sistema sea autodescriptivo.
4. Lógica de Predicados y Valores Nulos
- Lógica Ternaria: A diferencia de otros lenguajes, aquí se analiza el valor
NULLy cómo introduce un tercer estado lógico (unknown), algo fundamental para evitar errores en el diseño de consultas complejas.
5. Comparativa y Estandarización
- Dialectos y Estándares: El texto no se limita a un solo fabricante; ofrece una perspectiva comparada entre los estándares (SQL-92, SQL:1999) y las implementaciones reales en Oracle, IBM DB2, Informix y Microsoft SQL Server.
- Extensiones Procedimentales: El análisis de las extensiones (como PL/SQL o T-SQL) permite ver cómo SQL supera sus limitaciones declarativas para incluir control de flujo (bucles, condiciones).
Vamos a extender todos los conceptos a fondo. Pasemos ahora al DML (Data Manipulation Language), que es la parte del SQL que seguramente más utilices, ya que se encarga de la recuperación y modificación de los datos almacenados.
1. La potencia de la sentencia SELECT
Es la herramienta principal para consultar información. El texto destaca que no solo sirve para traer filas, sino para transformar los datos mientras se consultan:
- Distinct: Para eliminar duplicados de los resultados.
- Alias (AS): Para renombrar columnas en la salida del informe y que sean más legibles.
- Expresiones: Puedes realizar cálculos matemáticos directos en el SELECT (ej.
SELECT precio * 1.21 FROM productos).
2. El Filtrado con WHERE
El documento hace hincapié en el uso de operadores lógicos para precisar qué datos queremos:
- Operadores de comparación:
=,<>,<,>, etc. - Operadores lógicos:
AND,OR,NOT. Es vital entender su jerarquía para no obtener resultados erróneos. - Patrones (LIKE): El uso de
%(cualquier cadena) y_(un solo carácter) para búsquedas de texto parciales.
3. Agregación y Agrupamiento
Este es uno de los puntos más fuertes del análisis. El DML permite resumir grandes volúmenes de datos:
- Funciones de grupo:
SUM,AVG,MAX,MINyCOUNT. - GROUP BY: Agrupa los registros por una o más columnas para aplicar las funciones anteriores.
- HAVING: Es el «WHERE de los grupos». Solo se usa para filtrar los resultados después de haber agrupado (por ejemplo, para ver solo los departamentos cuyo gasto total sea mayor a 5000).
4. Modificación de datos (INSERT, UPDATE, DELETE)
A diferencia del DDL que modificaba la estructura, aquí modificamos el contenido:
- INSERT: Añade nuevas filas. Se puede hacer valor a valor o mediante el resultado de otra consulta.
- UPDATE: Modifica valores en filas existentes. ¡Ojo! El documento advierte (implícitamente por su estructura) que siempre debe ir acompañado de un
WHEREsi no quieres cambiar toda la tabla. - DELETE: Borra filas específicas. Al igual que el anterior, depende críticamente de la cláusula
WHERE.
5. Combinación de Tablas (JOINs)
El tema dedica un espacio importante a explicar cómo SQL reconstruye la información que está repartida en varias tablas relacionadas:
- INNER JOIN: Devuelve filas cuando hay una coincidencia en ambas tablas.
- LEFT/RIGHT JOIN: Devuelve todas las filas de una tabla y las coincidentes de la otra.
- FULL JOIN: Combina todos los registros de ambas tablas.
Ahora continuamos con el análisis del DML (Lenguaje de Manipulación de Datos) profundizando en uno de los conceptos más potentes y consultados: los JOINs (Combinaciones).
Este apartado es fundamental porque, en una base de datos relacional, la información suele estar normalizada y repartida en varias tablas. Los JOINs son la herramienta que permite «pegar» esas tablas para obtener una respuesta completa.
Existen diferentes formas de combinar tablas dependiendo de qué registros queramos conservar si no hay una coincidencia exacta:
1. INNER JOIN (Combinación Interna)
Es el más común. Devuelve únicamente las filas donde hay una coincidencia en ambas tablas basándose en una columna común (normalmente una clave primaria y una foránea).
- Ejemplo: Si consultas «Clientes» y «Pedidos», solo verás a los clientes que hayan realizado al menos un pedido.
2. LEFT OUTER JOIN (Combinación Externa Izquierda)
Devuelve todas las filas de la tabla de la izquierda (la primera que mencionas), y las filas coincidentes de la tabla de la derecha.
- Punto clave: Si no hay coincidencia en la derecha, el resultado mostrará valores
NULL. Es ideal para encontrar, por ejemplo, «todos los clientes y ver si tienen pedidos o no».
3. RIGHT OUTER JOIN (Combinación Externa Derecha)
Es el inverso del anterior. Prioriza todos los datos de la segunda tabla mencionada. Aunque es menos frecuente (ya que se puede lograr lo mismo invirtiendo el orden de las tablas en un LEFT JOIN), es parte del estándar.
4. FULL OUTER JOIN (Combinación Externa Completa)
Este comando devuelve todos los registros de ambas tablas. Cuando no hay coincidencia, rellena con NULL los campos de la tabla que falta. Es útil para diagnósticos de datos o para ver la unión total de dos entidades.
5. CROSS JOIN (Producto Cartesiano)
Combina cada fila de la primera tabla con todas y cada una de las filas de la segunda. El documento advierte que esto genera un número de filas igual al producto de ambas (si tienes 10 filas en una y 10 en otra, obtienes 100). Generalmente ocurre por error al olvidar la condición de unión.
Sintaxis Explícita vs. Implícita
El tema señala que existen dos formas de escribir estas uniones:
- Explícita: Usando la palabra
JOINy la cláusulaON(ej.SELECT * FROM A JOIN B ON A.id = B.id). Es la recomendada por el estándar actual. - Implícita: Listando las tablas en el
FROMy poniendo la condición de unión en elWHERE(ej.SELECT * FROM A, B WHERE A.id = B.id).
Las Subconsultas (Subqueries)
Un punto avanzado del DML es el uso de consultas dentro de otras consultas. El documento explica que se pueden usar en:
- El WHERE: Para filtrar datos basados en el resultado de otra consulta (ej. «empleados cuyo sueldo sea mayor que la media»).
- El FROM: Tratando el resultado de una consulta como si fuera una tabla temporal.
Vamos a ver un ejemplo práctico que combina JOINs, funciones de grupo y DML para que veas cómo se aplica todo lo anterior en una situación real.
Imagina que tenemos dos tablas: EMPLEADOS y DEPARTAMENTOS. Queremos obtener un informe que nos diga el nombre de cada departamento y el salario medio de sus empleados, pero solo para aquellos departamentos donde el salario medio sea superior a 2000€.

Análisis paso a paso de lo que ocurre aquí:
FROMyJOIN: El motor de la base de datos primero une ambas tablas usando el campo comúnid_dept. Esto es DML puro para relacionar entidades.GROUP BY: Una vez unidas, el sistema agrupa todas las filas de empleados que pertenecen al mismo nombre de departamento.AVG: Calcula el promedio de la columna salario para cada uno de esos grupos.HAVING: Aquí es donde aplicamos el filtro sobre el grupo. Si el promedio de un departamento es 1800€, esta cláusula lo descarta del resultado final.SELECT: Finalmente, se muestran solo las dos columnas que nos interesan.
Para profundizar en el DDL (Data Definition Language) según el documento, es fundamental entender cómo se construye la base de datos desde cero. Aquí tienes los aspectos más técnicos para completar este bloque:
Las Claves de la Sentencia CREATE TABLE
El documento destaca que crear una tabla no es solo nombrar columnas, sino definir el dominio y las restricciones de los datos.
- Tipos de Datos y Dominios: El DDL permite especificar qué tipo de información admite cada columna. El texto menciona la importancia de elegir correctamente entre:
- Cadenas:
CHAR(n)(longitud fija) vsVARCHAR(n)(longitud variable). - Números:
INTEGER,DECIMAL(p,s),FLOAT. - Temporales:
DATE,TIME,TIMESTAMP.
- Cadenas:
- Integridad de la Entidad (Clave Primaria): Se define mediante
PRIMARY KEY. Esto garantiza que cada fila sea única y que el campo identificador nunca sea nulo. - Integridad Referencial (Clave Ajena): Es quizás el punto más fuerte del DDL. Mediante
FOREIGN KEY ... REFERENCES, se vinculan tablas. El documento subraya las acciones referenciales que puedes definir:ON DELETE CASCADE: Si borras un registro padre, se borran automáticamente sus hijos.ON DELETE SET NULL: Si borras el padre, los hijos permanecen pero su referencia se pone a nulo.
Modificación y Eliminación: El Ciclo de Vida
Una vez creada la estructura, el DDL ofrece comandos para gestionarla sin necesidad de destruirla:
ALTER TABLE: Permite evolucionar el modelo. Puedes usarADDpara nuevas columnas,MODIFYpara cambiar tipos de datos oDROP COLUMNpara eliminar lo que ya no sirve.RENAME: Útil para cambiar el nombre de tablas o columnas si el modelo de negocio evoluciona.DROPvsTRUNCATE:DROP TABLEelimina la tabla del diccionario de datos (borra estructura y contenido).TRUNCATE TABLEes una operación de almacenamiento: libera el espacio de los datos pero mantiene la definición de la tabla para seguir usándola.
El Esquema y el Catálogo
Un detalle avanzado que menciona el tema es que el DDL no solo afecta a las tablas de usuario. Cada vez que ejecutamos estos comandos, el SGBD escribe en el Catálogo o Diccionario de Datos. Esto permite que el sistema sepa, por ejemplo, cuántas columnas tiene una tabla o qué restricciones debe validar antes de permitir un INSERT.
Pasamos al siguiente bloque: DCL (Data Control Language)
El DCL es el Lenguaje de Control de Datos. Según el documento, este bloque no se encarga de los datos en sí, sino de la seguridad y los privilegios. Sus dos comandos estrella son:
- GRANT (Conceder): Permite al administrador dar permisos a un usuario para realizar acciones específicas. Por ejemplo:
GRANT SELECT, INSERT ON empleados TO juan;. Con esto, el usuario «juan» solo podrá leer e insertar, pero no borrar. - REVOKE (Revocar): Se utiliza para retirar permisos previamente concedidos. Por ejemplo:
REVOKE UPDATE ON departamentos FROM maria;.
Conceptos clave del DCL en el tema:
- Privilegios de Sistema: Permisos para hacer cosas generales (conectarse a la base de datos, crear tablas).
- Privilegios de Objeto: Permisos sobre tablas o vistas específicas (ver, modificar, borrar).
- Roles: El documento menciona que, para facilitar la gestión, se pueden agrupar permisos en «Roles» (como un rol de ‘ADMIN’ o ‘LECTOR’) y asignar el rol directamente al usuario en lugar de darle permisos uno por uno.
Para cerrar el análisis de los bloques principales de SQL, vamos a profundizar en el TCL (Transaction Control Language) y las propiedades que garantizan que una base de datos sea robusta y fiable.
¿Qué es una Transacción?
Una transacción es una unidad lógica de trabajo que comprende una o varias sentencias SQL (como varios INSERT o UPDATE). El documento enfatiza que una transacción debe ejecutarse de forma completa o no ejecutarse en absoluto.
1. Comandos TCL
- COMMIT: Es el comando que confirma la transacción. Una vez ejecutado, todos los cambios realizados desde el inicio de la transacción se hacen permanentes en la base de datos y son visibles para otros usuarios.
- ROLLBACK: Es el comando de «arrepentimiento». Si algo falla durante el proceso, este comando deshace todos los cambios realizados en la transacción actual, devolviendo la base de datos al estado exacto en el que estaba antes de empezar.
- SAVEPOINT: Permite establecer puntos de control intermedios dentro de una transacción larga para poder hacer un rollback parcial hasta ese punto sin deshacer todo lo anterior.
2. Las Propiedades ACID
El punto fuerte del análisis teórico del tema es la explicación de las propiedades ACID, que son los cuatro requisitos que debe cumplir cualquier SGBD para asegurar que las transacciones sean seguras:
- Atocimidad (Atomicity): La transacción es «todo o nada». Si una parte falla, falla toda la operación.
- Consistencia (Consistency): Una transacción debe llevar la base de datos de un estado válido a otro estado válido, respetando todas las reglas de integridad (claves foráneas, checks, etc.).
- Aislamiento (Isolation): Las operaciones de una transacción son invisibles para otras transacciones concurrentes hasta que se confirme el cambio (COMMIT). Esto evita que alguien lea datos que aún están «a medias».
- Durabilidad (Durability): Una vez que se confirma la transacción (COMMIT), los cambios persistirán incluso si hay un fallo de energía o el sistema se reinicia.
3. Extensiones del Lenguaje (PL/SQL, T-SQL, etc.)
Finalmente, el documento cierra con una comparativa muy útil sobre cómo los distintos fabricantes han extendido el SQL estándar para añadir estructuras de programación (bucles, condicionales, variables):
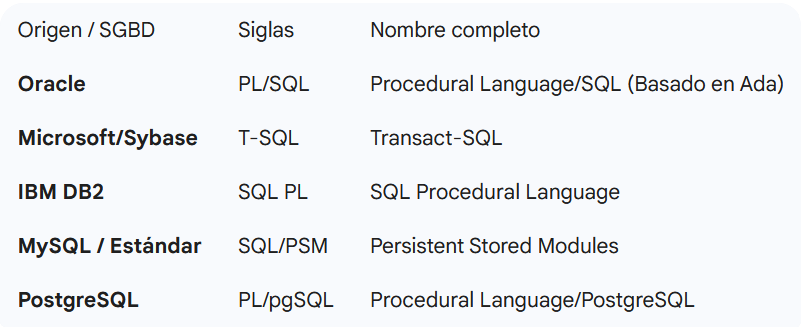
4. Resumen Final de Puntos de Análisis
Para concluir tu estudio del tema, estos son los conceptos clave que el documento destaca como fundamentales:
- Lógica Ternaria: Recordar que en SQL el valor
NULLimplica que las comparaciones pueden devolver Verdadero, Falso o Desconocido. - Diccionario de Datos: La capacidad del sistema para autodescribirse mediante tablas como
INFORMATION_SCHEMA. - Jerarquía de Operaciones: El orden en que se ejecutan las cláusulas (primero
FROM, luegoWHERE, despuésGROUP BY, etc.), lo cual es vital para no cometer errores en consultas complejas.
Vamos a profundizar en los detalles más específicos y avanzados que menciona el documento, centrándonos en el estándar SQL-92 y las particularidades del Diccionario de Datos, que son puntos clave para entender cómo funciona SQL «bajo el capó».
1. El Estándar SQL-92 (o SQL2)
El tema hace hincapié en que SQL-92 es la base de la mayoría de los sistemas actuales. De este estándar se destacan tres niveles de cumplimiento que los SGBD pueden implementar:
- Entry: El nivel básico que todos cumplen.
- Intermediate: Añade funcionalidades como esquemas y manipulación de tipos de datos más complejos.
- Full: El cumplimiento total del estándar (pocos sistemas comerciales lo implementan al 100% sin añadir sus propias variaciones).
2. Esquema, Catálogo y Diccionario de Datos
Este es uno de los apartados más técnicos del PDF. Explica que la base de datos se organiza de forma jerárquica:
- Esquema (Schema): Es una colección de objetos (tablas, vistas, etc.) que pertenecen a un mismo usuario o aplicación.
- Catálogo: Es un conjunto de esquemas.
- Diccionario de Datos: Es el corazón del SGBD. Contiene las definiciones de todos los objetos. El documento menciona que se puede consultar mediante vistas especiales como
INFORMATION_SCHEMA, lo que permite preguntar a la base de datos cosas como: «¿Qué columnas tiene la tabla X?» o «¿Qué usuario creó este índice?».
3. La Lógica Ternaria (3-Valued Logic)
Un punto fuerte del tema es la explicación de cómo SQL maneja la incertidumbre. Debido a la existencia de valores NULL (desconocidos), las comparaciones no solo devuelven Verdadero o Falso:
- True (Verdadero)
- False (Falso)
- Unknown (Desconocido): Resultado de comparar cualquier valor con un
NULL. - Impacto: Esto es crucial en el DML. Si una fila evaluada en un
WHEREresulta enUnknown, no se incluye en el resultado de la consulta.
4. Diferencias en Tipos de Datos entre Fabricantes
El documento ofrece una comparativa muy útil de cómo cambian los nombres de los tipos de datos según el gestor. Por ejemplo:
- Lo que en Oracle es un tipo
NUMBER, en otros sistemas puede serDECIMALoNUMERIC. - El manejo de cadenas largas: Oracle usa
LONGoCLOB, mientras que otros usanTEXToIMAGE.
5. Elementos Avanzados del Lenguaje
Finalmente, el texto detalla elementos que dan flexibilidad a las sentencias:
- Literales: Cómo escribir correctamente fechas o cadenas (normalmente entre comillas simples
' '). - Identificadores: Reglas para nombrar tablas y columnas (evitando palabras reservadas).
- Funciones Escalares: Transformaciones de datos fila por fila (como convertir a mayúsculas o extraer partes de una fecha).
 para Gestores")