Manual de Referencia: Estructura y Sintaxis de Mensajes HL7 v2
1 Introducción al Estándar HL7 v2
1.1 Fundamentos y Propósito de HL7
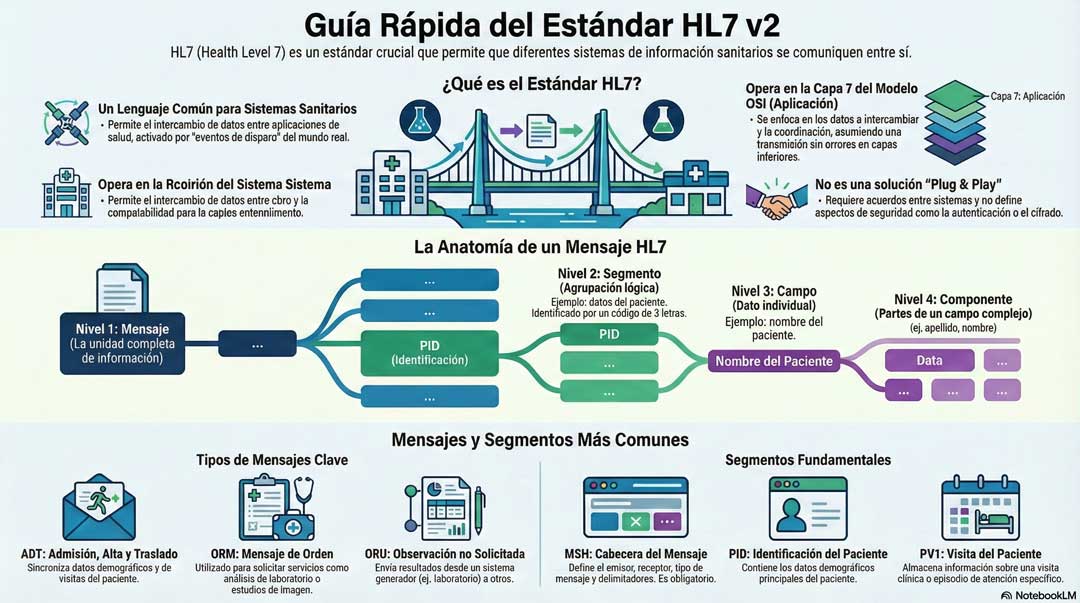
En el complejo ecosistema de los sistemas de información sanitarios, donde coexisten múltiples soluciones basadas en tecnologías diversas, la interoperabilidad es fundamental. La capacidad de que distintos sistemas se comuniquen de manera fluida y eficiente es crucial para la operativa clínica y administrativa. Para abordar este desafío, surgieron los estándares Health Level Seven (HL7), diseñados para definir un marco común para el intercambio y uso de información clínica y administrativa entre aplicaciones de software.
El nombre HL7 (Health Level 7) hace referencia directa al modelo de interconexión de sistemas abiertos (OSI). El estándar opera en el nivel 7, el nivel de Aplicación, lo que significa que se centra en los datos y la comunicación entre las aplicaciones finales, en respuesta a eventos del mundo real, en lugar de ocuparse de los niveles inferiores de la comunicación de red.
Los objetivos clave del estándar HL7 v2 son:
- Definición de los datos a intercambiar: Especifica qué información se debe enviar y su estructura.
- Coordinación de los intercambios: Establece las reglas y el flujo de la comunicación entre sistemas.
- Comunicación de errores específicos de la aplicación: Proporciona mecanismos para notificar fallos en el procesamiento del mensaje a nivel de la lógica de negocio.
Para evitar conceptos erróneos, es igualmente importante entender lo que HL7 no es:
- No es una aplicación de software.
- No es una especificación para el diseño de bases de datos.
- No es una arquitectura para diseñar sistemas hospitalarios.
- No es una especificación para un enrutador de mensajes.
El estándar HL7 presupone que la infraestructura de red subyacente garantiza ciertas condiciones para una transmisión satisfactoria:
- Transmisión sin errores: Se asume que la cadena de bytes transmitida se recibirá de forma íntegra y correcta, delegando la detección y corrección de errores a los niveles inferiores del modelo OSI.
- Conversión de caracteres: Si los sistemas emisor y receptor utilizan diferentes codificaciones de caracteres (ej. ASCII vs. EBCDIC), el entorno de comunicación es responsable de realizar la conversión necesaria.
- Ausencia de restricciones en el tamaño del mensaje: HL7 no impone límites al tamaño de un mensaje, dejando esta gestión a la capa de transporte.
Entender estos fundamentos nos permite adentrarnos en el ámbito de aplicación específico del estándar y sus limitaciones inherentes.
1.2 Ámbito de Aplicación y Limitaciones
Comprender las limitaciones del estándar HL7 es tan crucial como conocer sus capacidades. No se trata de una solución «plug and play»; una implementación exitosa requiere una visión clara de las áreas que el estándar no cubre. El principal obstáculo para una solución universal es la falta de estandarización en los propios procesos asistenciales, lo que obliga a los proveedores de software a desarrollar sistemas altamente flexibles.
HL7 intenta abarcar este amplio abanico de flujos de trabajo, lo que resulta en un estándar con un «exceso» de funcionalidades que ningún sistema implementa en su totalidad. Esto hace necesaria una fase de «negociación» entre los sistemas que se van a integrar para acordar qué subconjunto de características del estándar se utilizará, creando una especificación de interfaz adaptada a las necesidades locales.
Existen áreas críticas donde el estándar presenta limitaciones explícitas:
- Protección de la información: HL7 v2 no aborda la autenticación de los sistemas, la confidencialidad de los datos ni especifica ningún método de cifrado para el transporte de mensajes. Asume que la infraestructura de seguridad necesaria es proporcionada por las aplicaciones y la red.
- Roles y Relaciones: El estándar no define las relaciones o roles entre las distintas entidades (pacientes, médicos, etc.). Esta lógica debe ser gestionada por las propias aplicaciones.
- Registros de Auditoría: HL7 no contempla la gestión de registros de auditoría, un componente clave para crear entornos robustos y auditables que debe ser implementado de forma externa.
Con una comprensión clara del alcance de HL7, podemos explorar el paradigma conceptual que impulsa toda la comunicación: el evento.
2 El Paradigma de HL7: Mensajería Orientada a Eventos
El modelo conceptual de HL7 se basa en una premisa sencilla: un acontecimiento en el mundo real genera la necesidad de intercambiar información entre sistemas. Este acontecimiento se denomina «evento disparador» (trigger event).
Por ejemplo, cuando un paciente es admitido en un hospital (el evento en el mundo real), se produce un evento disparador (A01 - Admisión de paciente) que causa la necesidad de que el sistema de admisión (HIS) notifique a otros sistemas (laboratorio, farmacia, facturación) sobre el nuevo ingreso.
El «Mensaje» es la unidad atómica de información transferida entre sistemas para comunicar este evento. Cada mensaje se define por una combinación de su «Tipo de Mensaje» (un código de 3 caracteres que define el propósito general, como ADT para «Admisión, Alta y Transferencia») y el «Evento Disparador» específico.
La relación entre tipos de mensaje y eventos es jerárquica:
- Un tipo de mensaje (
ADT) puede estar asociado a múltiples eventos (A01– Admisión,A08– Modificación de datos, etc.). - Un evento disparador (
A01), sin embargo, solo puede estar asociado a un único tipo de mensaje (ADT).
El estándar también permite la extensibilidad. Cuando se necesitan flujos de trabajo no contemplados, las organizaciones pueden definir mensajes y eventos personalizados, que por convención deben comenzar con la letra «Z».
Los mensajes se pueden clasificar en dos patrones de comunicación principales:
- Actualizaciones no solicitadas: La comunicación es iniciada por el sistema que controla el evento. Por ejemplo, cuando un sistema de laboratorio finaliza un análisis, envía un mensaje con los resultados a la historia clínica electrónica sin que esta lo haya solicitado previamente. La respuesta esperada es simplemente un acuse de recibo (
ACK) que confirma que el mensaje fue recibido correctamente. - Consulta y respuesta: La comunicación es iniciada por una aplicación que solicita información a otra. Por ejemplo, un sistema clínico puede consultar a un sistema departamental por los resultados de un paciente específico. En este caso, la respuesta esperada no es solo un
ACK, sino un mensaje que contiene la información solicitada.
Ahora que entendemos el concepto de mensaje y su propósito, podemos analizar cómo se define su estructura formal.
3 Anatomía de un Mensaje HL7: De la Estructura al Dato
Un mensaje HL7 tiene una estructura jerárquica bien definida, compuesta por segmentos, campos y componentes. El formato de cada tipo de mensaje se define mediante una gramática formal conocida como «mensaje abstracto», que establece los bloques de construcción y las reglas de ensamblaje.
3.1 Estructura Abstracta del Mensaje
El propósito del «mensaje abstracto» es definir qué segmentos contiene un mensaje, su orden secuencial, y si su presencia y repetición son obligatorias, opcionales o condicionales.
Por ejemplo, la estructura abstracta para un tipo de mensaje de admisión podría ser:
MSH, EVN, PID, [{NK1}],PV1, [PV2],[{OBX}],[AL1]
La sintaxis de corchetes y llaves determina la opcionalidad y cardinalidad de cada segmento:
| Sintaxis | Significado |
(sin corchetes) | Obligatorio (exactamente 1 ocurrencia) |
[...] | Opcional (0 a 1 ocurrencia) |
{...} | Requerido y repetible (1 a N ocurrencias) |
[{...}] | Opcional y repetible (0 a N ocurrencias) |
3.2 Segmentos, Campos y Componentes
Segmento Un segmento es una agrupación lógica de campos de datos relacionados que representa una unidad de información específica. Cada segmento se identifica por un código único de 3 caracteres llamado «Segmento ID» (ej. MSH para la cabecera, PID para la identificación del paciente).
A continuación se muestra un ejemplo de un mensaje real, compuesto por múltiples segmentos:
MSH|^~\&|NSI||LAB||20010827120759||ADT^A01|NSI1|P|2.3||||AL
EVN|A01|18000101000000
PID|1||60719^^^^HI|26690949^^^^DNI|TORRALBA^AIDA||19780113000000|F|||POT OSI 4032 108^^CAPITAL FEDERAL^^1899
NK1|1|CAMUS^ALBERTO|PAD|RIVADAVIA 253|42539686
PV1|1|I|301|R|||1436^PEREZ^JORGE^ALBERTO|1026^LOPEZ^NORBERTO|998^GARCIA^ALEJANDRO|M|||A|4|A0|N|1026^LOPEZ^NORBERTO|OB|H0100240|||||||||||||||||||ALV||||||||20010823095130|20010823102455
IN1|1|INT^^HI|2^^^^HI~347^^^^NSI|PLAN DE SALUD
El tipo de mensaje y el evento disparador se definen en el campo 9 del segmento MSH: |ADT^A01|.
Campo de Datos Un segmento está compuesto por una secuencia ordenada de campos de datos, separados por un delimitador. La definición formal de cada segmento se especifica en el estándar mediante una tabla que detalla cada uno de sus campos.
Definición de Segmento La tabla de definición de un segmento describe sus campos y es fundamental для los desarrolladores. Las columnas más importantes son:
- SEQ: El orden secuencial del campo dentro del segmento.
- LEN: La longitud máxima sugerida para el campo.
- DT: El Tipo de Dato que define el formato del campo.
- OPT: La opcionalidad del campo.
- El.NAME: El nombre descriptivo del campo.
Los códigos de Opcionalidad (OPT) definen si un campo debe estar presente:
- R: Requerido. El campo debe tener un valor.
- O: Opcional. El campo puede estar presente o no.
- C: Condicional. La obligatoriedad del campo depende del valor de otros campos.
- X: No usar. El campo está obsoleto y no debe utilizarse.
- B: Para compatibilidad con versiones anteriores.
Componente Un campo puede estar, a su vez, subdividido en partes más pequeñas llamadas componentes. La estructura de un campo complejo viene determinada por su tipo de dato. Un ejemplo clásico es el nombre del paciente, que se compone de apellido, nombre, iniciales, etc. En el mensaje de ejemplo, el campo 5 del segmento PID (PID-5) contiene |TORRALBA^AIDA|, que está compuesto por dos componentes: apellido (TORRALBA) y nombre (AIDA).
Comprender esta jerarquía estructural es el primer paso. A continuación, examinaremos las reglas sintácticas que permiten a los sistemas construir e interpretar correctamente esta estructura.
4 Sintaxis y Reglas de Procesamiento
Los caracteres delimitadores y las reglas de codificación son la gramática fundamental del lenguaje HL7. Dominarlos es esencial para la correcta construcción e interpretación de los mensajes, garantizando que la información sea procesada sin ambigüedades por el sistema receptor.
4.1 Caracteres Delimitadores y de Escape
Los mensajes HL7 utilizan un conjunto de caracteres especiales para delimitar los diferentes niveles de su estructura. Estos delimitadores se definen en los campos 1 y 2 del segmento MSH, lo que permite flexibilidad, aunque en la práctica casi siempre se utilizan los valores por defecto.
MSH|^~\&|...
| Delimitador | Carácter Común | Función |
| Terminador de Segmento | <CR> (ASCII 13) | Finaliza cada línea o segmento. Es el único delimitador que no se puede cambiar. |
| Separador de Campo | ` | ` (ASCII 124) |
| Separador de Componente | ^ (ASCII 94) | Separa componentes adyacentes dentro de un campo. |
| Carácter de Repetición | ~ (ASCII 126) | Separa múltiples ocurrencias de un campo (cuando la definición del campo lo permite). |
| Separador de Subcomponente | & (ASCII 38) | Separa subcomponentes adyacentes dentro de un componente. |
| Carácter de Escape | \ (ASCII 92) | Se utiliza para representar caracteres especiales dentro del texto o para aplicar formato. |
El carácter de escape (\) tiene tres propósitos principales:
- Representar un carácter delimitador como texto literal.
- Aplicar un formato simple al texto (ej. texto enfatizado).
- Representar caracteres hexadecimales.
Las secuencias de escape más comunes son:
| Secuencia | Descripción |
\H\ | Inicia texto enfatizado (resaltado). |
\N\ | Vuelve a texto normal (finaliza el enfatizado). |
\F\ | Representa el separador de campo (` |
\S\ | Representa el separador de componente (^). |
\R\ | Representa el separador de repetición (~). |
\T\ | Representa el separador de subcomponente (&). |
\E\ | Representa el propio carácter de escape (\). |
\Xdddd...\ | Representa uno o más caracteres hexadecimales. |
\Zdddd\ | Secuencia local de escape. |
\Cxxyy\ | Cambio a secuencia de caracteres normal. |
\Mxxyyzz\ | Cambio a secuencia de caracteres multibyte. |
4.2 Reglas de Codificación y Recepción
El estándar define un conjunto de reglas para garantizar que los mensajes se construyan y se procesen de manera consistente.
Reglas para Enviar un Mensaje
- Codificar cada segmento en el orden exacto especificado por el formato abstracto del mensaje.
- Cada segmento debe comenzar con su ID de 3 caracteres.
- Cada campo debe estar precedido por el separador de campos.
- Codificar cada campo en el orden especificado por la tabla de definición del segmento.
- Los campos que no están presentes no requieren ningún carácter; se representan por la ausencia de datos entre separadores (
...||...). - Los campos que están presentes pero cuyo valor es nulo deben codificarse explícitamente con dos comillas dobles (
...|""|...). - Se pueden omitir los separadores finales para componentes o subcomponentes al final de un campo si no están presentes.
- Se pueden omitir los separadores de campo finales en un segmento si los campos restantes no están presentes.
- Finalizar cada segmento con el carácter terminador de segmento (
<CR>).
Reglas para Recibir un Mensaje
- Si un segmento esperado no se recibe, sus campos deben tratarse como no presentes.
- Si se recibe un segmento que no se esperaba según la definición del mensaje, se debe ignorar. No es un error.
- Si se reciben campos adicionales no esperados al final de un segmento, también deben ser ignorados.
Estas reglas de recepción son cruciales para mantener la compatibilidad hacia adelante y hacia atrás. Dado que las implementaciones varían según la «negociación» entre sistemas, un receptor robusto debe ser tolerante a datos inesperados o ausentes, según lo definido por la especificación de interfaz local.
Con la sintaxis y las reglas de procesamiento establecidas, podemos ahora profundizar en el contenido: los tipos de datos que definen el formato de cada campo.
5 Catálogo de Tipos de Datos HL7
Cada campo en un segmento HL7 tiene un tipo de dato asociado que define la estructura y el formato de su contenido. Estos tipos de datos garantizan que la información, como fechas, nombres o valores codificados, se represente de manera consistente. Se pueden clasificar en básicos (con un solo componente) y agregados (compuestos por múltiples componentes).
5.1 Tipos de Datos Alfanuméricos
- ST (String): Una cadena de caracteres. Se utiliza generalmente para datos de aplicación, no para texto libre introducido por un usuario.
- TX (Text): Un bloque de texto destinado a la visualización o impresión, con un tamaño máximo de hasta 64k. En este tipo de dato, el carácter
~se interpreta como un salto de línea. - FT (Formatted Text): Similar a TX, pero admite códigos de formato embebidos para controlar la presentación del texto (ej. sangrías, saltos de línea).
5.2 Tipos de Datos Numéricos
- NM (Numeric): Un número representado como una cadena de caracteres, que puede incluir un signo y un punto decimal.
- SI (Sequence ID): Un entero positivo utilizado como identificador de secuencia.
- CQ (Composite Quantity with Units): Un tipo agregado para representar una cantidad y sus unidades. Está compuesto por una cantidad (NM) y unas unidades (CWE). Por ejemplo:
|123.7^kg|. - MO (Money): Un tipo agregado para representar una cantidad monetaria y su divisa. Está compuesto por una cantidad (NM) y una denominación (ID). Por ejemplo:
|31.23^EUR|. - SN (Structured Numeric): Se utiliza para expresar resultados clínicos de forma no ambigua, admitiendo comparadores (ej.
>,<) y separadores para rangos o ratios. Por ejemplo:|>^100|.
5.3 Tipos de Datos Temporales
- DT (Date): Una fecha con el formato
YYYY[MM[DD]]. - TM (Time): Una hora con el formato
HH[MM[SS[.S[S[S]]]]]][+/-ZZZZ]. - DTM (Date/Time): Una fecha y hora combinadas, con el formato
YYYY[MM[DD[HH[MM[SS[.S[S[S]]]]]]]][+/-ZZZZ].
5.4 Tipos de Datos de Identificadores
- ID (Valor codificado por HL7): Un valor cuyo contenido debe pertenecer a una tabla de códigos definida y publicada por el estándar HL7.
- IS (Valor codificado por el usuario): Un valor cuyo contenido debe pertenecer a una tabla de códigos definida localmente por las partes que implementan la interfaz.
- HD (Hierarchic Designator): Identifica una entidad responsable de la gestión de un conjunto de identificadores, como un sistema o una aplicación.
- EI (Entity Identifier): Se utiliza para identificadores generados automáticamente por un sistema.
5.5 Tipos de Datos Varios
- RP (Reference Pointer): Transmite información sobre datos almacenados en otro sistema, actuando como un puntero.
- PL (Person Location): Especifica la ubicación física de una persona dentro de una institución sanitaria.
5.6 Tipos de Datos para Valores Codificados
- CF (Coded Element with Formatted Values): Transmite un código junto con su texto descriptivo asociado en formato FT.
- CNE (Coded with No Exceptions): Representa un valor de una tabla de codificación externa (ej. LOINC, SNOMED). La tabla de códigos referenciada no puede ser extendida localmente.
- CWE (Coded with Exceptions): Tiene la misma estructura que CNE, pero permite el uso de códigos locales que no están en la tabla de referencia externa, proporcionando mayor flexibilidad.
- CX (Extended Composite ID with check digit): Un identificador complejo que incluye un número, un dígito de control y la autoridad que lo asigna.
5.7 Tipos de Datos Demográficos
- (X)AD ((Extended) Address): Se utiliza para codificar direcciones postales.
- FN (Family Name): Un tipo agregado para representar apellidos, diseñado con la internacionalización en mente.
- (X)PN ((Extended) Person Name): Un tipo de dato complejo y agregado para representar el nombre completo de una persona, con componentes para nombre, apellidos, prefijos, sufijos, etc.
El conocimiento de estos tipos de datos es crucial, ya que son los bloques de construcción del contenido dentro de los mensajes y segmentos que exploraremos a continuación.
6 Mensajes Relevantes y sus Estructuras
Esta sección sirve como guía de referencia rápida para algunos de los tipos de mensajes más comunes en las integraciones HL7, detallando su propósito y estructura abstracta.
6.1 ADT (Admit/Visit Notification)
Los mensajes ADT (Admisión, Alta y Transferencia) son la columna vertebral de la sincronización de datos de pacientes. Se utilizan para comunicar eventos relacionados con la gestión de pacientes, como ingresos, traslados, modificaciones de datos demográficos o altas. La respuesta esperada a un mensaje ADT es un mensaje ACK.
MSH
[{ SFT }]
[ UAC ]
EVN
PID
[ PD1 ]
[{ ARV }]
[{ ROL }]
[{ NK1 }]
PV1
[ PV2 ]
[{ ARV }]
[{ ROL }]
[{ DB1 }]
[{ OBX }]
[{ AL1 }]
[{ DG1 }]
[ DRG ]
[{
PR1
[{ ROL }]
}]
[{ GT1 }]
[{
IN1
[ IN2 ]
[ IN3 ]
[{ ROL }]
}]
[ ACC ]
[ UB1 ]
[ UB2 ]
[ PDA ]
6.2 ACK (Acknowledgment)
El mensaje ACK es un acuse de recibo general. Se utiliza para responder a un mensaje recibido, indicando si ha sido aceptado y procesado correctamente. Sus componentes principales son los segmentos MSH y MSA, que se detallan en la sección 7.0. El segmento MSA contiene un código que indica el resultado del procesamiento.
6.3 ORM (Order Message)
El mensaje ORM es un mensaje de petición general utilizado para solicitar un servicio para un paciente. Es comúnmente usado para enviar peticiones a sistemas departamentales, como una solicitud de análisis al laboratorio (LIS) o un estudio de imagen al sistema de radiología (RIS). La respuesta esperada a un ORM es un mensaje ORR (General Order Response).
MSH
[{
NTE
}]
[
PID
[ PD1 ]
[{ NTE }]
[
PV1
[ PV2 ]
[{
IN1
[ IN2 ]
[ IN3 ]
}]
[ GT1 ]
[{ AL1 }]
]
{
ORC
[
<OBR|RQD|RQ1|RXO|ODS>
[{ NTE }]
[{ CTD }]
[{ DG1 }]
[{
OBX
[{ NTE }]
}]
]
[{ FT1 }]
[{ CTI }]
}
]
6.4 ORU (Unsolicited Pre-Ordered Point-Of-Care Observation)
Los mensajes ORU se utilizan para enviar resultados y observaciones de un sistema productor (como un LIS o un RIS) a un sistema consumidor (como una historia clínica electrónica). Se denominan «no solicitados» porque el envío es iniciado por el sistema que genera los resultados, sin una petición previa. La respuesta esperada es un ACK.
6.5 SIU (Scheduling Information Unsolicited)
Los mensajes SIU se utilizan para comunicar información relacionada con la gestión de citas y agendas de pacientes. Permiten notificar eventos como la creación de una nueva cita (SIU-S12), la reprogramación (SIU-S13) o la cancelación (SIU-S15) a los sistemas involucrados. La respuesta esperada es un ACK.
Estos mensajes se construyen a partir de un conjunto de segmentos fundamentales. A continuación, analizaremos los más importantes.
7 Análisis de Segmentos Fundamentales
Aunque un mensaje puede contener docenas de segmentos, un pequeño grupo de ellos son fundamentales y aparecen en casi todas las transacciones. Esta sección desglosa la función y los campos clave de estos segmentos esenciales.
7.1 MSH – Message Header
El segmento MSH (Cabecera del Mensaje) es obligatorio y debe ser el primer segmento en cada mensaje HL7. Contiene metadatos cruciales sobre el propio mensaje y la transacción.
- Función Principal: Identificar el emisor y el receptor, el tipo de mensaje, la fecha de envío y los delimitadores utilizados.
- Campos Relevantes:
- MSH-3 (Sending Application): Identifica la aplicación que envía el mensaje.
- MSH-5 (Receiving Application): Identifica la aplicación de destino.
- MSH-9 (Message Type): Define el propósito del mensaje. Se compone de tres partes: el código del mensaje (ej.
ADT), el evento disparador (ej.A08) y la estructura del mensaje (ADT_A01). Es importante notar que varios eventos pueden compartir la misma estructura. Por convención, la estructura se nombra con el código del evento de menor valor numérico. Por ello, un mensaje de actualización de datos de paciente (A08) se codificaría comoADT^A08^ADT_A01, indicando que, aunque el evento esA08, utiliza la misma estructura que el evento de admisión (A01). - MSH-11 (Processing ID): Indica el entorno de procesamiento (ej.
Ppara Producción,Tpara Pruebas,Dpara Desarrollo).
7.2 MSA – Message Acknowledgment
El segmento MSA es el componente principal de un mensaje de respuesta ACK. Proporciona un resumen del estado de procesamiento del mensaje original.
- Función Principal: Confirmar la recepción de un mensaje e indicar si fue aceptado o rechazado.
- Campos Relevantes:
- MSA-1 (Acknowledgment Code): Un código que indica el resultado. Los valores más comunes son
AA(Aceptado),AE(Error de Aplicación, indica un error de sintaxis o estructura en el mensaje recibido) yAR(Rechazado por la Aplicación, indica un error en la lógica de negocio, como un paciente desconocido o una petición no válida).
- MSA-1 (Acknowledgment Code): Un código que indica el resultado. Los valores más comunes son
7.3 PID – Patient Identification
El segmento PID es uno de los más importantes del estándar y se utiliza para transportar la información demográfica principal de un paciente.
- Función Principal: Contener datos de identificación y demográficos del paciente que no cambian con frecuencia.
- Campos Relevantes:
- PID-3 (Patient Identifier List): Un campo repetible que contiene los diversos identificadores del paciente (número de historia clínica, DNI, etc.).
- PID-5 (Patient Name): El nombre legal completo del paciente, utilizando el tipo de dato
XPN.
7.4 PV1 – Patient Visit
Mientras que el segmento PID contiene información permanente del paciente, el PV1 contiene datos relacionados con una visita o encuentro clínico específico (una hospitalización, una visita a urgencias, etc.).
- Función Principal: Proporcionar información contextual sobre una visita o episodio clínico concreto.
- Campos Relevantes:
- PV1-2 (Patient Class): Clasifica el tipo de visita (ej.
Ipara Paciente hospitalizado,Opara Paciente ambulatorio,Epara Urgencias). Sus valores sugeridos se definen en la tabla HL7 0004.
- PV1-2 (Patient Class): Clasifica el tipo de visita (ej.
Aunque el formato de «pipes and hats» es la representación tradicional, HL7 también proporciona una codificación alternativa basada en XML.
8 Codificación Alternativa: HL7 v2.x en formato XML
A partir de la versión 2.3.1 del estándar, se introdujo una codificación alternativa al formato tradicional de delimitadores («pipes and hats») basada en XML. La especificación y la semántica del mensaje son idénticas en ambas representaciones; la elección de una u otra depende del acuerdo técnico establecido entre los sistemas emisor y receptor.
La estructura jerárquica de un mensaje HL7 v2.x se mapea directamente a la estructura de un documento XML:
| Parte del Mensaje | Estructura XML |
| Estructura del mensaje | Elemento raíz |
| Segmento | Elemento |
| Campo | Elemento |
| Componente | Elemento |
| Tipo de dato del campo | Atributo fijo del elemento correspondiente al campo y elemento <appinfo> |
| Nombre del campo y abreviatura | Atributo fijo del elemento correspondiente al campo y elemento <documentation> |
| Tablas de referencia | Atributo fijo del elemento |
Para ilustrar la diferencia, a continuación se muestra el mismo segmento MSH en ambos formatos.
Formato Tradicional («Pipes and Hats»)
MSH|^~\&|||||20100927172936||ADT^A01|MSG00001|P|2.6|
Formato XML Equivalente
<MSH>
<MSH.1 Type="ST" Table="HL70000" LongName="Field Separator">|</MSH.1>
<MSH.2 Type="ST" Table="HL70000" LongName="Encoding Characters">^~\&</MSH.2>
<MSH.7 Type="DTM" Table="HL70000" LongName="Date/Time of Message">20100927172936</MSH.7>
<MSH.9 Type="MSG" Table="HL70000" LongName="Message Type">
<MSG.1 Type="ID" LongName="Message Code">ADT</MSG.1>
<MSG.2 Type="ID" LongName="Trigger Event">A01</MSG.2>
<MSG.3 Type="ID" LongName="Message Structure">ADT_A01</MSG.3>
</MSH.9>
<MSH.10 Type="ST" Table="HL70000" LongName="Message Control ID">MSG00001</MSH.10>
<MSH.11 Type="PT" Table="HL70000" LongName="Processing ID">
<PT.1>P</PT.1>
</MSH.11>
<MSH.12 Type="VID" Table="HL70000" LongName="Version ID">
<VID.1>2.6</VID.1>
</MSH.12>
</MSH>
Este manual ha cubierto los elementos esenciales de la sintaxis, estructura y componentes clave de HL7 v2, proporcionando una base sólida para desarrolladores e integradores que trabajan con este estándar crítico para la interoperabilidad sanitaria.
9. HL7 Versión 3 (V3): El cambio de paradigma
Mientras que la V2 es un estándar «basado en mensajes» y delimitadores (pipes), la V3 se diseñó para ser un estándar «basado en modelos» y orientado a objetos, utilizando XML como sintaxis de intercambio.
9.1. El Modelo de Información de Referencia (RIM)
La base de HL7 V3 es el RIM (Reference Information Model). Es el modelo de datos maestro que representa todas las clases de información de salud y sus relaciones.
- En V2, el estándar era «flexible» (cada hospital lo adaptaba).
- En V3, el estándar es «estricto»: todo debe derivar del RIM para asegurar que no haya ambigüedad semántica.
9.2. Diferencias clave para el examen (V2 vs. V3)
| Característica | HL7 Versión 2.x | HL7 Versión 3 |
| Sintaxis | Delimitadores de texto (pipes |) | XML |
| Modelado | Ad-hoc (basado en la experiencia) | Formal (basado en el RIM) |
| Flexibilidad | Muy alta (implica negociación) | Baja (orientado a la precisión) |
| Interoperabilidad | Sintáctica (llega el dato) | Semántica (se entiende el significado) |
| Implementación | Más sencilla y ligera | Compleja y pesada (gran overhead) |
9.3. El Estándar CDA (Clinical Document Architecture)
Dentro de la V3, el éxito más importante que debes conocer es el CDA.
- No es un mensaje de intercambio rápido (como un ingreso), sino un estándar para el intercambio de documentos clínicos (informes de alta, historias clínicas, etc.).
- Utiliza XML y permite que el documento sea leído tanto por máquinas como por humanos.
10. El Futuro: HL7 FHIR (Fast Healthcare Interoperability Resources)
En las oposiciones actuales ya están preguntando por FHIR (pronunciado «fire»). Es el intento de HL7 de unir lo mejor de los dos mundos:
- La sencillez y facilidad de implementación de la V2.
- La potencia semántica y el rigor del modelo de la V3.
Características de FHIR que debes memorizar:
- Se basa en «Recursos» (la unidad mínima de información: Paciente, Medicación, Procedimiento).
- Utiliza tecnologías web modernas: APIs RESTful, formatos JSON (además de XML) y OAuth para seguridad.
- Es mucho más rápido de implementar que la V3.
 para Gestores")